Unlock the value of your data to make profitable marketing, media, assortment and pricing decisions.
All from one centralised AI platform.


Data science + AI + insight = decision intelligence.
![]()
Unify your data sources.
Unify customer, product and click data in a single platform.
![]()
Apply AI without code.
Apply data science, machine learning and AI without knowing a line of code.
![]()
Make data-led decisions.
Know your customers, products, relationships… know your decisions.
![]()
Drive business growth.
Analyse your data and identify actions to maximise commercial growth.
The better* way for retailers and brands to make decisions.
*Because data science shouldn’t feel like rocket science.
Why HyperFinity?
The retail landscape is ever-changing. We help retailers and brands solve their biggest problems when it comes to data and insight.
Hiring is tough.
The world’s chronic lack of data scientists and AI specialists means hiring and keeping talent is incredibly challenging and expensive.
Outdated platforms.
You’re looking for an easily accessible, affordable data science and AI tool, built for everyone in your business – not just data scientists.
Siloed data.
Technology, data and insight are spread across your business, resulting in disjointed decisions and poor customer experiences.
Culture shift.
You need embedded data science and AI capability for ongoing decision making, rather than a one-off, expensive consultancy project.


Much more than just a software provider.
We’ve spent decades working in and consulting for some of the biggest names in retail and consumer products.
We’ve helped them make smarter, unified and customer-led decisions with their data.
We’re with you every step of the way.

Use data and intelligence to drive commercial results.
Increase profitability.

Reduce operating costs.

Increase conversion and loyalty.
Bring your customers and products closer together.
Find out what’s really driving customer behaviour.
Join the dots between your customers and products.
Take the guesswork out of key product decisions.
Improve your decisions across interlinked business areas.

Trusted by leading retailers and brands.



The world’s leading retailers and brands are using decision intelligence.
Companies using data science and AI to make intelligent, customer-centric decisions significantly outperform those who don’t.
Decision intelligence is a huge opportunity for retailers and brands to make smarter commercial decisions and ultimately increase revenue and profit.
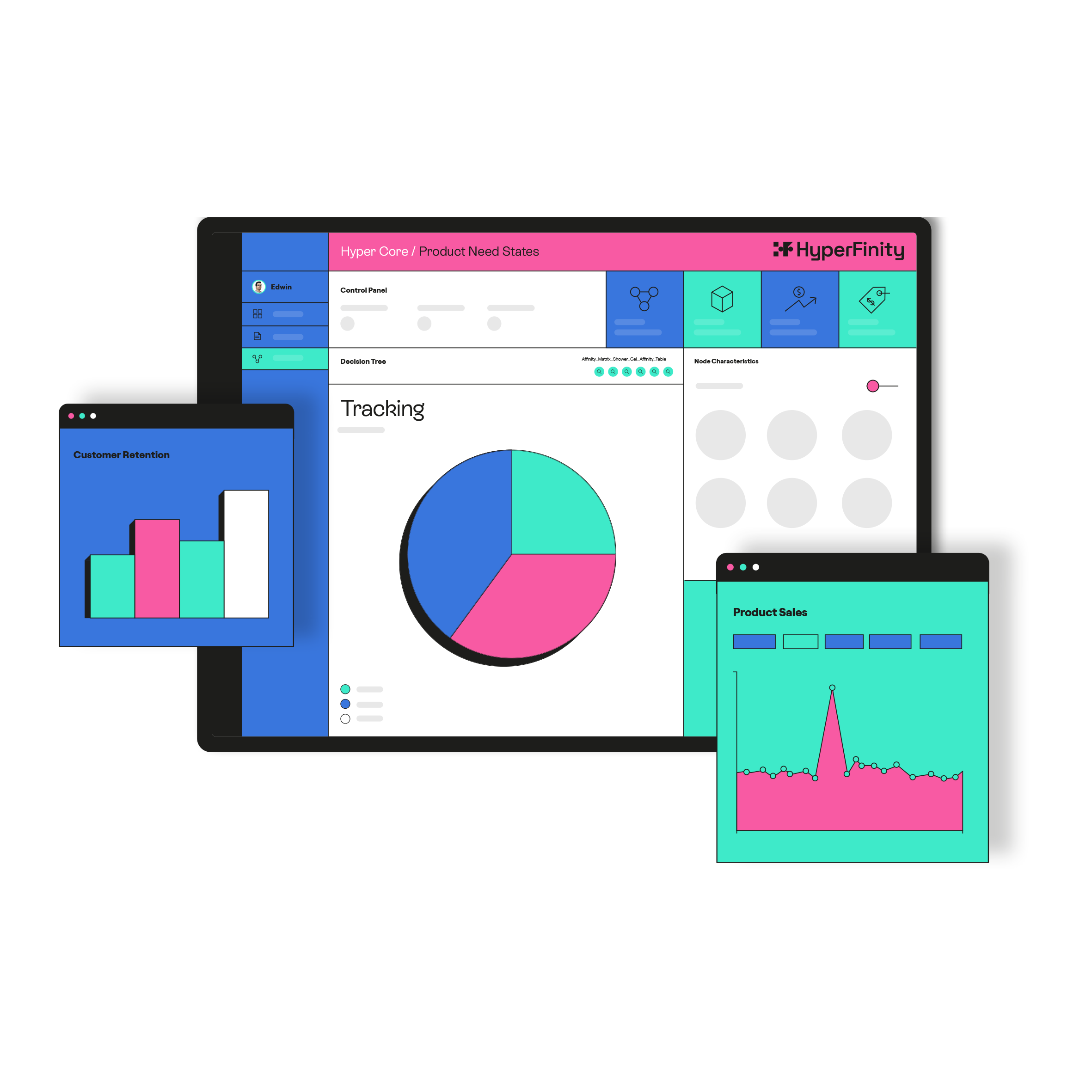
Our cloud-based decision intelligence platform uses cutting edge data science and AI to create decision intelligence.
Rapidly analyse your customer and product data, then identify which actions will maximise your commercial growth.
The best part? Anyone can use it.

Relationships. It’s what we do.
Delivering data-led transformation.

"Through their data science expertise and retail optimisation toolset, Hyper are helping Studio to deliver against our goal of data-led transformation. We find Hyper to be highly skilled and very pragmatic in their approach to using data science to solve genuine commercial challenges and improve customer experience."
Ed Child
Head of Enterprise Data, Studio
An essential partner.
"Hyper have proven an essential partner to Beaverbrooks. Demonstrating strong technical skills, empathy and clear enthusiasm to support our goals of using data and insight to deliver truly engaging and memorable customer experiences."
Charlotte Lord
Marketing Manager, Beaverbrooks
Find out how far
HyperFinity can
take you.
Decision intelligence
is seeing HyperFinity
in action.

